stompy.spatial — Spatial analysis, data management and manipulation.¶
For GIS-related operations, and spatial tools to support model development and data analysis.
algorithms¶
General geometric algorithms that do not fit cleanly into more special-purpose modules.
field¶
Various classes representing a 2D scalar-valued function. Useful for bathymetry processing, creating parameter maps for model input. Includes both point-based and raster-based classes.
-
class
stompy.spatial.field.BinopField(A, op, B)[source]¶ Bases:
stompy.spatial.field.FieldCombine arbitrary fields with binary operators
-
class
stompy.spatial.field.CompositeField(shp_fn=None, factory=None, priority_field='priority', data_mode='data_mode', alpha_mode='alpha_mode', shp_data=None, shp_query=None, target_date=None)[source]¶ Bases:
stompy.spatial.field.FieldIn the same vein as BlenderField, but following the model of raster editors like Photoshop or the Gimp.
Individual sources are treated as an ordered “stack” of layers.
Layers higher on the stack can overwrite the data provided by layers lower on the stack.
A layer is typically defined by a raster data source and a polygon over which it is valid.
Each layer’s contribution to the final dataset is both a data value and an alpha value. This allows for blending/feathering between layers.
The default “data_mode” is simply overlay. Other data modes like “min” or “max” are possible.
The default “alpha_mode” is “valid()” which is essentially opaque where there’s valid data, and transparent where there isn’t. A second common option would probably be “feather(<distance>)”, which would take the valid areas of the layer, and feather <distance> in from the edges.
The sources, data_mode, alpha_mode details are taken from a shapefile.
Alternatively, if a factory is given, it should be callable and will take a single argument - a dict with the attributse for each source. The factory should then return the corresponding Field.
TODO: there are cases where the alpha is so small that roundoff can cause artifacts. Should push these cases to nan. TODO: currently holes must be filled manually or after the fact. Is there a clean way to handle that? Maybe a fill data mode?
- Create a polygon shapefile, with fields:
priority numeric data_mode string alpha_mode string
These names match the defaults to the constructor. Note that there is no reprojection support – the code assumes that the shapefile and all source data are already in the target projection. Some code also assumes that it is a square projection.
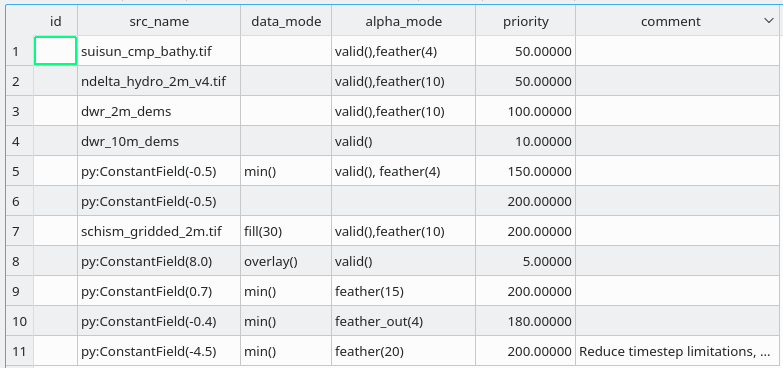
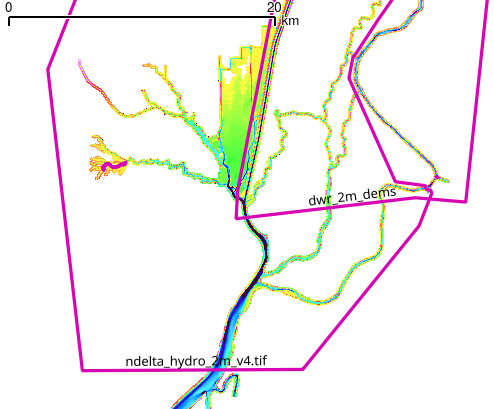
Each polygon in the shapefile refers to a source dataset and defines where that dataset will be used.

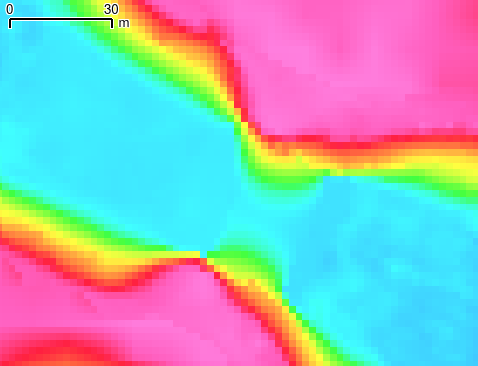
Datasets are processed as layers, building up from the lowest priority to the highest priority. Higher priority sources generally overwrite lower priority source, but that can be controlled by specifying data_mode. The default is overlay(), which simple overwrites the lower priority data. Other common modes are
- min(): use the minimum value between this source and lower priority data. This layer will only deepen areas.
- max(): use the maximum value between this source and lower priority data. This layer will only raise areas.
- fill(dist): fill in holes up to dist wide in this datasets before proceeding.
Multiple steps can be chained with commas, as in fill(5.0),min(), which would fill in holes smaller than 5 spatial units (e.g. m), and then take the minimum of this dataset and the existing data from previous (lower priority) layers.
Another example:
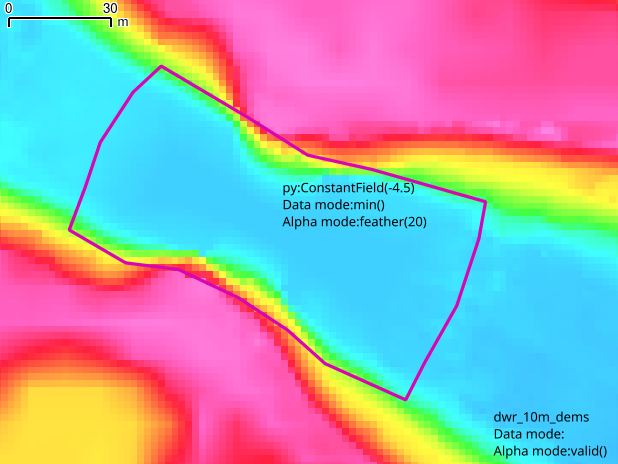
-
projection= None¶
-
to_grid(nx=None, ny=None, bounds=None, dx=None, dy=None, mask_poly=None)[source]¶ render the layers to a SimpleGrid tile. nx,ny: number of pixels in respective dimensions bounds: xxyy bounding rectangle. dx,dy: size of pixels in respective dimensions. mask_poly: a shapely polygon. only points inside this polygon will be generated.
-
class
stompy.spatial.field.ConstantField(c)[source]¶ Bases:
stompy.spatial.field.Field
-
class
stompy.spatial.field.ConstrainedScaleField(X, F, projection=None, from_file=None)[source]¶ Bases:
stompy.spatial.field.XYZFieldLike XYZField, but when new values are inserted makes sure that neighboring nodes are not too large. If an inserted scale is too large it will be made smaller. If a small scale is inserted, it’s neighbors will be checked, and made smaller as necessary. These changes are propagated to neighbors of neighbors, etc.
As points are inserted, if a neighbor is far enough away, this will optionally insert new points along the edges connecting with that neighbor to limit the extent that the new point affects too large an area
-
add_point(pnt, value, allow_larger=False)[source]¶ Insert a new point into the field, clearing any invalidated data and returning the index of the new point
-
check_scale(i, old_value=None)[source]¶ old_value: if specified, on each edge, if the neighbor is far enough away, insert a new node along the edge at the scale that it would have been if we hadn’t adjusted this node
-
r= 1.1¶
-
safety_factor= 0.85¶
-
-
class
stompy.spatial.field.CurvilinearGrid(X, F, projection=None)[source]¶
-
class
stompy.spatial.field.Field(projection=None)[source]¶ Bases:
objectSuperclass for spatial fields
-
envelope(eps=0.0001)[source]¶ Return a rectangular shapely geometry the is the bounding box of this field.
-
reproject(from_projection=None, to_projection=None)[source]¶ Reproject to a new coordinate system. If the input is structured, this will create a curvilinear grid, otherwise it creates an XYZ field.
-
to_grid(nx=None, ny=None, interp='linear', bounds=None, dx=None, dy=None, valuator='value')[source]¶ bounds is a 2x2 [[minx,miny],[maxx,maxy]] array, and is required for BlenderFields bounds can also be a 4-element sequence, [xmin,xmax,ymin,ymax], for compatibility with matplotlib axis(), and Paving.default_clip.
- specify one of:
- nx,ny: specify number of samples in each dimension dx,dy: specify resolution in each dimension
interp used to default to nn, but that is no longer available in mpl, so now use linear.
-
value(X)[source]¶ in density_field this was called ‘scale’ - evaluates the field at the given point or vector of points. Some subclasses can be configured to interpolate in various ways, but by default should do something reasonable
-
-
class
stompy.spatial.field.Field3D(projection=None)[source]¶ Bases:
stompy.spatial.field.Field
-
class
stompy.spatial.field.FunctionField(func)[source]¶ Bases:
stompy.spatial.field.Fieldwraps an arbitrary function function must take one argument, X, which has shape […,2]
-
class
stompy.spatial.field.GdalGrid(filename, bounds=None, geo_bounds=None)[source]¶ Bases:
stompy.spatial.field.SimpleGridA specialization of SimpleGrid that can load single channel and RGB files via the GDAL library. Use this for loading GeoTIFFs, some GRIB files, and other formats supported by GDAL.
-
class
stompy.spatial.field.GtxGrid(filename, is_vertcon=False, missing=9999, projection='WGS84')[source]¶
-
class
stompy.spatial.field.MultiRasterField(raster_file_patterns, **kwargs)[source]¶ Bases:
stompy.spatial.field.FieldGiven a collection of raster files at various resolutions and with possibly overlapping extents, manage a field which picks from the highest resolution raster for any given point.
Assumes that any point of interest is covered by at least one field (though there may be slower support coming for some sort of nearest valid usage).
There is no blending for point queries! If two fields cover the same spot, the value taken from the higher resolution field will be returned.
Basic bilinear interpolation will be utilized for point queries.
Edge queries will resample the edge at the resolution of the highest datasource, and then proceed with those point queries
Cell/region queries will have to wait for another day
Some effort is made to keep only the most-recently used rasters in memory, since it is not feasible to load all rasters at one time. to this end, it is most efficient for successive queries to have some spatial locality.
-
clip_max= inf¶
-
dx¶
-
dy¶
-
error_on_null_input= 'any'¶
-
extract_tile(xxyy=None, res=None)[source]¶ Create the requested tile from merging the sources. Resolution defaults to resolution of the highest resolution source that falls inside the requested region
-
max_count= 20¶
-
offset= 0.0¶
-
open_count= 0¶
-
order= 1¶
-
serial= 0¶
-
to_grid(nx=None, ny=None, interp='linear', bounds=None, dx=None, dy=None, valuator='value')[source]¶ Extract data in a grid. currently only nearest, no linear interpolation.
-
-
class
stompy.spatial.field.PyApolloniusField(X=None, F=None, r=1.1, redundant_factor=None)[source]¶ Bases:
stompy.spatial.field.XYZFieldTakes a set of vertices and the allowed scale at each, and extrapolates across the plane based on a uniform telescoping rate
-
insert(xy, f)[source]¶ directly insert a point into the Apollonius graph structure note that this may be used to incrementally construct the graph, if the caller doesn’t care about the accounting related to the field - returns False if redundant checks are enabled and the point was deemed redundant.
-
static
read_shps(shp_names, value_field='value', r=1.1, redundant_factor=None)[source]¶ Read points or lines from a list of shapefiles, and construct an apollonius graph from the combined set of features. Lines will be downsampled at the scale of the line.
-
to_grid(*a, **k)[source]¶ use the delaunay based griddata() to interpolate this field onto a rectilinear grid. In theory interp=’linear’ would give bilinear interpolation, but it tends to complain about grid spacing, so best to stick with the default ‘nn’ which gives natural neighbor interpolation and is willing to accept a wider variety of grids
Here we use a specialized implementation that passes the extent/stride array to interper, since lin_interper requires this.
interp=’qhull’: use scipy’s delaunay/qhull interface. this can additionally accept a radius which limits the output to triangles with a smaller circumradius.
-
-
class
stompy.spatial.field.QuadrilateralGrid(projection=None)[source]¶ Bases:
stompy.spatial.field.FieldCommon code for grids that store data in a matrix
-
class
stompy.spatial.field.SimpleGrid(extents, F, projection=None)[source]¶ Bases:
stompy.spatial.field.QuadrilateralGridA spatial field stored as a regular cartesian grid. The spatial extent of the field is stored in self.extents (as xmin,xmax,ymin,ymax) and the data in the 2D array self.F
-
default_interpolation= 'nearest'¶
-
downsample(factor, method='decimate')[source]¶ - method: ‘decimate’ just takes every nth sample
- ‘ma_mean’ takes the mean of n*n blocks, and is nan
- and mask aware.
-
extract_tile(xxyy=None, res=None, match=None, interpolation='linear', missing=nan)[source]¶ Create the requested tile xxyy: a 4-element sequence match: another field, assumed to be in the same projection, to match
pixel for pixel.- interpolation: ‘linear’,’quadratic’,’cubic’ will pass the corresponding order
- to RectBivariateSpline.
‘bilinear’ will instead use simple bilinear interpolation, which has the added benefit of preserving nans.
missing: the value to be assigned to parts of the tile which are not covered by the source data.
-
fill_by_convolution(iterations=7, smoothing=0, kernel_size=3)[source]¶ Better for filling in small seams - repeatedly applies a 3x3 average filter. On each iteration it can grow the existing data out by 2 pixels. Note that by default there is not a separate smoothing process - each iteration will smooth the pixels from previous iterations, but a pixel that is set on the last iteration won’t get any smoothing.
Set smoothing >0 to have extra iterations where the regions are not grown, but the averaging process is reapplied.
If iterations is ‘adaptive’, then iterate until there are no nans.
-
fill_by_griddata()[source]¶ Basically griddata - limits the input points to the borders of areas missing data. Fills in everything within the convex hull of the valid input pixels.
-
gdalwarp= 'gdalwarp'¶
-
gradient()[source]¶ compute 2-D gradient of the field, returning a pair of fields of the same size (one-sided differences are used at the boundaries, central elsewhere). returns fields: dFdx,dFdy
-
int_nan= -9999¶
-
mask_outside(poly, value=nan, invert=False, straddle=None)[source]¶ Set the values that fall outside the given polygon to the given value. Existing nan values are untouched.
Compared to polygon_mask, this is slow but allows more options on exactly how to test each pixel.
- straddle: if None, then only test against the center point
- if True: a pixel intersecting the poly, even if the center is not inside, is accepted. [future: False: reject straddlers]
-
polygon_mask(poly, crop=True, return_values=False)[source]¶ similar to mask_outside, but: much faster due to outsourcing tests to GDAL returns a boolean array same size as self.F, with True for pixels inside the polygon.
crop: if True, optimize by cropping the source raster first. should provide identical results, but may not be identical due to roundoff.
- return_vales: if True, rather than returning a bitmask the same size
- as self.F, return just the values of F that fall inside poly. This can save space and time when just extracting a small set of values from large raster
-
shape¶
-
smooth_by_convolution(kernel_size=3, iterations=1)[source]¶ Repeatedly apply a 3x3 average filter (or other size: kernel_size). Similar to the smoothing step of fill_by_convolution, except that the effect is applied everywhere, not just in the newly-filled areas.
-
to_xyz()[source]¶ The simple grid version is a bit smarter about missing values, and tries to avoid creating unnecessarily large intermediate arrays
-
trace_contour(vmin, vmax, union=True)[source]¶ Trace a filled contour between vmin and vmax, returning a single shapely geometry (union=True) or a list of polygons (union=False). Uses matplotlib to do the actual contour construction.
Note that matplotlib is not infallible here, and complicated or large inputs can create erroneous output. gdal_contour might help.
-
value(X)[source]¶ in density_field this was called ‘scale’ - evaluates the field at the given point or vector of points. Some subclasses can be configured to interpolate in various ways, but by default should do something reasonable
-
value_on_edge(e, samples=None, **kw)[source]¶ Return the value averaged along an edge - the generic implementation just takes 5 samples evenly spaced along the line, using value()
-
warp(t_srs, s_srs=None, fn=None, extra='')[source]¶ interface to gdalwarp t_srs: string giving the target projection s_srs: override current projection of the dataset, defaults to self._projection fn: if set, the result will retained, written to the given file. Otherwise
the transformation will use temporary files. opts: otherextra: other options to pass to gdalwarp
-
warp_to_match(target)[source]¶ Given a separte field trg, warp this one to match pixel for pixel.
self and target should have meaningful projection().
-
-
class
stompy.spatial.field.TileMaker(f, **kwargs)[source]¶ Bases:
objectGiven a field, create gridded tiles of the field, including some options for blending, filling, cropping, etc.
-
dx= 2¶
-
dy= 2¶
-
filename_fmt= '%(left).0f-%(bottom).0f.tif'¶
-
fill_iterations= 10¶
-
force= False¶
-
output_dir= '.'¶
-
quantize= True¶
-
smoothing_iterations= 5¶
-
tx= 1000¶
-
ty= 1000¶
-
-
class
stompy.spatial.field.XYZField(X, F, projection=None, from_file=None)[source]¶ Bases:
stompy.spatial.field.Field-
add_point(pnt, value)[source]¶ Insert a new point into the field, clearing any invalidated data and returning the index of the new point
-
cs2cs(src='+proj=utm +zone=10 +datum=NAD27 +nadgrids=conus', dst='+proj=utm +zone=10 +datum=NAD83')[source]¶ In place modification of coordinate system. Defaults to UTM NAD27 -> UTM NAD83
-
default_interpolation= 'linear'¶
-
intersect(other, op, radius=0.1)[source]¶ Create new pointset that has points that are in both fields, and combine the values with the given operator op(a,b)
-
inv_dist_interp(p, min_radius=None, min_n_closest=None, clip_min=-inf, clip_max=inf, default=None)[source]¶ inverse-distance weighted interpolation This is a bit funky because it tries to be smart about interpolation both in dense and sparse areas.
min_radius: sample from at least this radius around p min_n_closest: sample from at least this many points
-
listener_count= 0¶
-
outside_hull_fallback= True¶
-
rectify(dx=None, dy=None)[source]¶ Convert XYZ back to SimpleGrid. Assumes that the data fall on a regular grid. if dx and dy are None, automatically find the grid spacing/extents.
-
to_grid(nx=2000, ny=2000, interp='linear', bounds=None, dx=None, dy=None, aspect=1.0, max_radius=None)[source]¶ use the delaunay based griddata() to interpolate this field onto a rectilinear grid. In theory interp=’linear’ would give bilinear interpolation, but it tends to complain about grid spacing, so best to stick with the default ‘nn’ which gives natural neighbor interpolation and is willing to accept a wider variety of grids
Here we use a specialized implementation that passes the extent/stride array to interper, since lin_interper requires this.
interp=’qhull’: use scipy’s delaunay/qhull interface. this can additionally accept a radius which limits the output to triangles with a smaller circumradius.
-
-
class
stompy.spatial.field.ZLevelField(X, Z, F)[source]¶ Bases:
stompy.spatial.field.Field3DOne representation of a 3-D field. We have a set of XY points and a water column associated with each. Extrapolation pulls out the closest water column, and extends the lowest cell if necessary.
-
stompy.spatial.field.random()¶ random_sample(size=None)
Return random floats in the half-open interval [0.0, 1.0).
Results are from the “continuous uniform” distribution over the stated interval. To sample \(Unif[a, b), b > a\) multiply the output of random_sample by (b-a) and add a:
(b - a) * random_sample() + a
- size : int or tuple of ints, optional
- Output shape. If the given shape is, e.g.,
(m, n, k), thenm * n * ksamples are drawn. Default is None, in which case a single value is returned.
- out : float or ndarray of floats
- Array of random floats of shape size (unless
size=None, in which case a single float is returned).
>>> np.random.random_sample() 0.47108547995356098 >>> type(np.random.random_sample()) <type 'float'> >>> np.random.random_sample((5,)) array([ 0.30220482, 0.86820401, 0.1654503 , 0.11659149, 0.54323428])
Three-by-two array of random numbers from [-5, 0):
>>> 5 * np.random.random_sample((3, 2)) - 5 array([[-3.99149989, -0.52338984], [-2.99091858, -0.79479508], [-1.23204345, -1.75224494]])
gen_spatial_index¶
A generic interface to several implementations of spatial indexes.
interp_4d module¶
A heat-diffusion method for interpolating sparse data in space and time onto a grid. This can be used to take point samples collected over time and create a spatially smooth interpolation which respects shorelines and other features in a computational grid.
interp_coverage¶
Special-purpose constrained linear interpolation. Used by some methods in field.
join_features¶
Join many line segments into topologically consistent rings or polygons (potentially with holes). Useful if you have a shoreline made of many line segments, but want a single shoreline polyline or polygon.
-
stompy.spatial.join_features.arc_to_close_line(points, n_arc_points=40)[source]¶ Given a list of points, return an arc that closes the linestring, and faces away from the centroid of the points
-
stompy.spatial.join_features.clean_degenerate_rings(point_lists, degen_shpname='degenerate_rings.shp')[source]¶ Given a list of lists of points - filter out point lists which represent degenerate rings, writing the invalid rings to a shapefile degen_shpname, and returning a list of only the valid rings. Unclosed linestrings are passed through.
set degen_shpname to None to disable that output.
-
stompy.spatial.join_features.lines_to_polygons(new_features, close_arc=False, single_feature=True, force_orientation=True, return_open=False, min_area=0.0)[source]¶ returns a list of Polygons and a list of features which were not part of a polygon force_orientation: ensure that interior rings have negative signed area return_open: if True, allow open linestrings, but they will be returned in a 3rd item. min_area: prune polygons with area below this threshold
-
stompy.spatial.join_features.lines_to_polygons_slow(new_features, close_arc=False, single_feature=True, force_orientation=True)[source]¶ single_feature: False is not yet implemented! returns a list of Polygons and a list of features which were not part of a polygon force_orientation: ensure that interior rings have negative signed area
-
stompy.spatial.join_features.merge_lines(layer=None, segments=None)[source]¶ Given an ogr LineString layer, merge linestrings by matching endpoints, and return a list of arrays of points.
if layer is given, it should be an ogr LineString layer if segments is given, it should be a list of numpy arrays, where each array is [N,2] giving points along a path.
this version only handles exact matches between endpoints
-
stompy.spatial.join_features.process_layer(orig_layer, output_name, tolerance=0.0, create_polygons=False, close_arc=False, single_feature=True, remove_duplicates=True)[source]¶ - remove_duplicates: if true, exactly duplicated nodes along a single path will be removed, i.e.
- the linestring A-B-B-C will become A-B-C.
single_feature: only save the biggest feature
-
stompy.spatial.join_features.progress_message(str, steps_done=None, steps_total=None)¶
kdtree_spatialindex¶
Wrapper for using scipy’s kdtree as a spatial index.
linestring_utils¶
Simple methods for resampling a polyline to higher or lower resolution.
-
stompy.spatial.linestring_utils.downsample_linearring(points, density, factor=None, closed_ring=1)[source]¶ Makes sure that points aren’t too close together Allow them to be 0.3*density apart, but any edges shorter than that will lose one of their endpoints.
-
stompy.spatial.linestring_utils.left_normals(linestring)[source]¶ For each point in the [N,2] linestring find the left-pointing unit normal vector, returned in a [N,2] array.
proj_utils¶
A few utility functions related to geographic projections, mainly the mapper() function.
Bundle up common projection operations
qgis_spatialindex module¶
A wrapper for using the QGIS spatial index class in stompy.
robust_predicates module¶
A pure python implementation of Jonathan Shewchuk’s robust geometric predicates. Exact evaluation of tests for collinearity (does point A fall left/right/on a line joining points B,C), and in-circle (does point D fall inside/outside/on a circle defined by points A,B,C).
wkb2shp module¶
Read and write data to/from shapefiles.
Functions for reading and writing shapefiles.
These are simple wrappers around OGR and Shapely libraries.
-
stompy.spatial.wkb2shp.shp2geom(shp_fn, use_wkt=False, target_srs=None, source_srs=None, return_srs=False, query=None, fold_to_lower=False)[source]¶ Read a shapefile into memory as a numpy array. Data is returned as a record array, with geometry as a shapely geometry object in the ‘geom’ field.
target_srs: input suitable for osgeo.osr.SetFromUserInput(), or an existing osr.SpatialReference, to specify a projection to which the data should be projected. If this is specified but the shapefile does not specify a projection, and source_srs is not given, then an exception is raised. source_srs will override the projection in the shapefile if specified.
fold_to_lower: fold field names to lower case.
- return_srs: return a tuple, second item being the text representation of the project, or
- None if no projection information was found.
-
stompy.spatial.wkb2shp.wkb2shp(shp_name, input_wkbs, srs_text='EPSG:26910', field_gen=<function <lambda>>, fields=None, overwrite=False, geom_type=None, driver=None, layer_name=None)[source]¶ Save data to a shapefile.
shp_name: filename.shp for writing the result or ‘MEMORY’ to return an in-memory ogr layer.
- input_wkbs: list of shapely geometry objects for each feature. They must all
- be the same geometry type (no mixing lines and polygons, etc.)
- There are three ways of specifying fields:
- field_gen: a function which will be called once for each feature, with
- the geometry as its argument, and returns a dict of fields.
fields: a numpy structure array with named fields, or fields: a dict of field names, with each dictionary entry holding a sequence
of field values.
srs_text: sets the projection information when writing the shapefile. Expects a string, for example ‘EPSG:3095’ or ‘WGS84’.
- driver: Directly specify an alternative driver, such as GPKG. if None, assumed
- shapefile, unless shp_name is ‘memory’ in which case create an in-Memory layer. for GPKG, the optional layer_name argument can be used to name the layer which would default to the basename of the shp_name otherwise